A Million Requests Walk Into a Server — The Philosophy Behind Distributed Systems
Table of Contents
Your favourite app serves millions of people simultaneously without breaking a sweat. Nobody told you how unsettling the machinery behind that actually is.

Somewhere right now, approximately 500 million people are opening Instagram. They're loading stories, liking photos, sending messages. Every single one of them is getting a response in under a second.
There is no computer on Earth powerful enough to do that alone.
This is the quiet miracle of distributed systems — and also the source of some of the most genuinely hard problems in all of computer science. Not hard in the "needs more calculus" way. Hard in the "we've been arguing about the right answer since the 1980s and still haven't fully resolved it" way.
Pull up a chair.
The obvious solution that doesn't work
When you first think about scaling a system, the instinct is obvious: get a bigger machine. More RAM, faster CPU, more disk. This is called vertical scaling — and it works, right up until it doesn't.
The problem is that individual machines have hard physical limits. At some point, there's no "bigger machine" to buy. The biggest servers money can buy top out well before the demand that Instagram, Zomato, Google, or any serious platform at scale actually generates.
So you do the next obvious thing: you add more machines. Spread the load. This is horizontal scaling — and it is, genuinely, the right answer. The catch is that the moment you put data and computation across multiple machines, you've created a fundamentally new class of problems that don't exist on a single computer.
Analogy Imagine you're running a restaurant with a single cash register. One person handles everything — orders, payments, receipts. Now you scale: five registers, five cashiers. Faster, yes. But now if two cashiers accidentally sell the last table to different customers, you have a consistency problem. If one cashier's register crashes, you have an availability problem. If the cashier can't reach the kitchen to confirm stock, you have a partition problem.
The theorem that broke every architect's brain
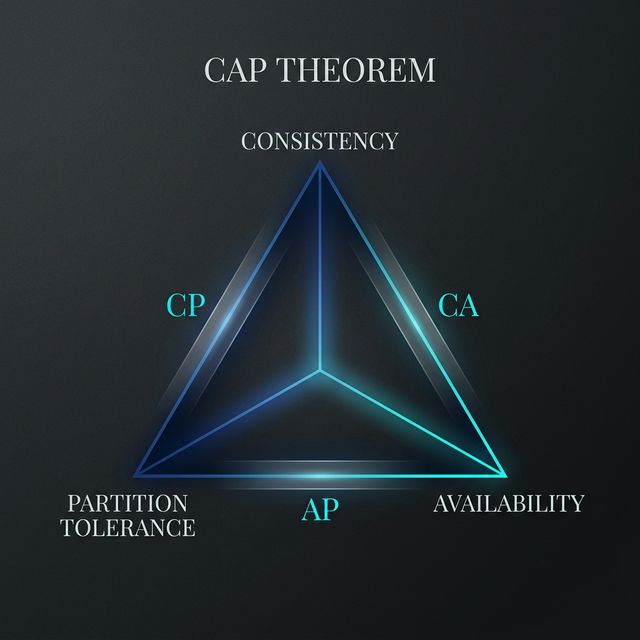
In 1999, Eric Brewer proposed the CAP theorem. It states three things you want from a distributed system:
- Consistency: every node returns the same data at the same time.
- Availability: every request gets a response.
- Partition Tolerance: the system keeps working even when the network breaks.
The cruel punchline: Network failures are not optional. Which means the real choice is always between consistency and availability when things go wrong. Do you want your system to give the right answer, or do you want it to give an answer?
"The CAP theorem doesn't tell you what to build. It tells you what you're giving up — and forces you to be honest about it."
Two philosophies, one internet
The CAP theorem bifurcated the database world into two camps:
- CP systems (Consistent + Partition Tolerant): will refuse to answer if they can't guarantee correctness. Banks and stock trading platforms use these.
- AP systems (Available + Partition Tolerant): always answer, even if the data is stale. Amazon's shopping cart and your Instagram feed are AP.
Analogy Think of it as a WhatsApp group chat versus a bank transfer. Nobody cares if your message shows as "delivered" a few milliseconds later. But if your bank transfer shows as "sent" on your side and "not received" on theirs because of a blip, that is a catastrophe.
The hard problem — consensus
How exactly do you make multiple machines agree on a single truth, when any of them could fail at any moment? This is the consensus problem.
The most famous solution is Raft — designed specifically to be something human beings could actually understand. Raft works by electing a leader. The leader replicates writes to followers, confirming they're committed only when a majority acknowledge it. If the leader dies, a new one is automatically elected.
"Raft didn't solve a new problem. It solved an old problem in a way that engineers could finally implement without losing their minds."
The everyday abstractions hiding all of this
Every time you call a REST API or hit a database, there's a distributed systems problem being solved below the surface. This invisibility is an extraordinary achievement, but it's dangerous when things break.
A system that works perfectly at 100 requests/second can behave mysteriously at 100,000. Understanding the tradeoffs—like why a cache is AP or why a primary database is CP—is what separates a junior developer from a systems engineer.
The part where it gets genuinely weird
The tricky frontier is what happens at thousands of nodes: Byzantine fault tolerance. This assumes nodes can actively lie or try to deceive the others.
And even when networks are fine, there's the PACELC theorem: the tradeoff between latency and consistency. Every millisecond counts. This is why Google Spanner uses GPS atomic clocks to synchronize data centers on different continents.
Why any of this matters to you, right now
Distributed systems are no longer an advanced topic; they're the foundation of modern software. The million requests walking into that server aren't magic. They're geometry — sharding, replication, and consensus.
Once you see the machinery, the magic gets better, not worse.
